一文搞懂go并发编程设计原理
前言
主要学习其设计原则,大体流程,权衡利弊
不要纠结于部分难懂的实现细节,因为不同的人对相同接口的实现细节不一样,就算是相同的人实现两次也可能不一样
context
context的作用主要有两个:
-
在整个请求的执行过程中传递一些业务无关的数据,例如userId,logId,避免所有方法都要加这些参数
- 其他语言,例如java用过ThreadLocal实现该功能
-
控制整个链路的取消,超时

-
一般将context.Context作为方法的第一个参数,就算现阶段用不着也建议加上,减少后期代码修改。除非明确知道不需要context的功能,例如util,helper包下的工具方法
-
context不应该作为结构体的字段:
- context代表一个请求上下文,只应该在该请求的生命周期内被使用
- 如果放到结构体里,请求的生命周期结束后还能访问该ctx,违背了context的设计原则,除非这个结构体的生命周期和请求相同,例如http.Request
valueCtx
通过funcWithValue(parent Context, key, val any) Context可以向ctx中并发安全地设置一个键值对
-
为什么需要并发安全?
- ctx可以在不同goroutine之间传递,如果不同goroutine同时往ctx中读写数据,就会有并发问题
-
如果我们来设计会如何实现?
- map:不是并发安全
- sync.Map:可以满足要求,但go没有这么做
go通过创建新context来实现:
func WithValue(parent Context, key, val any) Context {if parent == nil {panic("cannot create context from nil parent")}if key == nil {panic("nil key")}if !reflectlite.TypeOf(key).Comparable() {panic("key is not comparable")}// 创建新contextreturn &valueCtx{parent, key, val}
}
```go例如下面的例子,会构造出很多层contextfunc main() {
ctx := context.TODO()
ctxa := context.WithValue(ctx, “a”, “aa”)
ctxb := context.WithValue(ctxa, “b”, “bb”)
ctxc := context.WithValue(ctxb, “c”, “cc”)
}
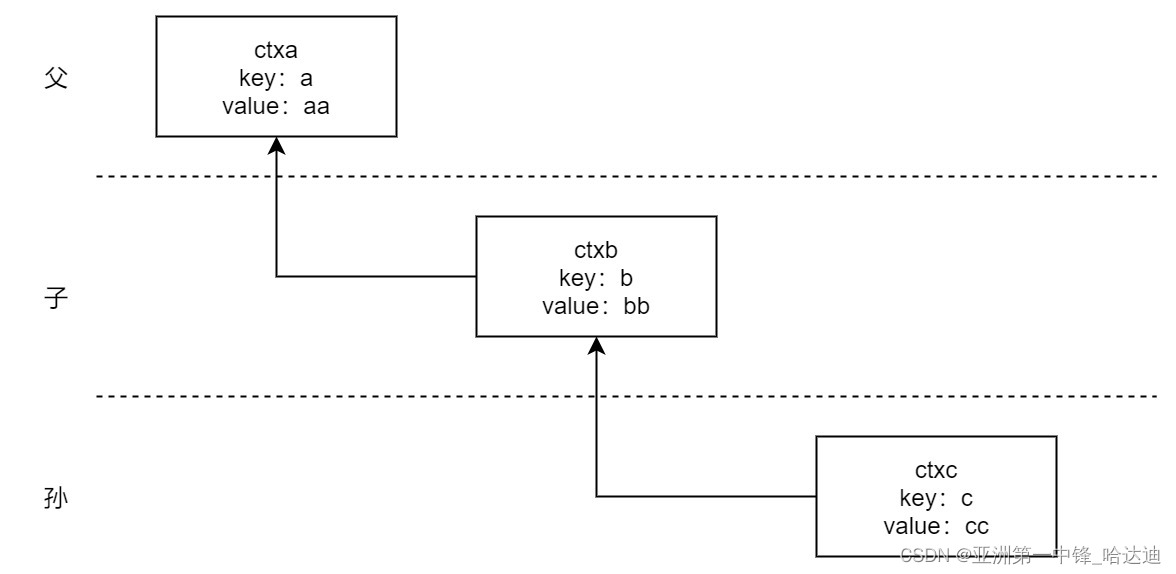查找value就是先看自己的key是否和参数相同,如果相同返回自己的value,否则去父节点找```go
func (c *valueCtx) Value(key any) any {if c.key == key {return c.val}return value(c.Context, key)
}
注意事项
-
父context无法获取子context设置的kv
-
因为从父contetx向上的路径中,无法找到子context设置的kv
-
当然可以可以绕开这个限制,父context放个map进去,这样子context对该map的修改父也能看到
- 不推荐,因为违反了ctx中数据不可变的特性
-
-
如果父的链条中有两个节点的key相同,会返回离自己最近的节点的value
设计要点
-
为什么不用map存储,而是用类似链表的方式存储数据?
- context的设计理念是不可变
-
为什么链表方式串联数据是并发安全的?因为其巧妙地使用了子节点指向父节点的串联方式:
- 读:当一个context创建好后,从自己往父的链表是固定的,无法被修改
- 写:将自己追加到一个链表中这个操作,只会在各自的goroutine中进行
-
用链表存储数据的优劣势:
- 优势:实现简单,不用加锁就能实现并发 安全
- 劣势:层级较多时性能较低,因此gin.Context采用map来实现
cancelCtx
通过funcWithCancel(parent Context) (ctx Context, cancel CancelFunc)
创建出可以取消的ctx
type cancelCtx struct {Contextmu sync.Mutex// 一个channel,当能从channel读取数据时,表示该context被关闭 done atomic.Value// 维护子context,本context被关闭时,同时会关闭子的 children map[canceler]struct{} err error
}
当调用WithCancel返回的cancel方法时,可以取消所有监听该ctx和子ctx的goroutine
- 并不是调用了cancel就会平白无故地取消子goroutine,需要在子goroutine里需要配合监听ctx.Done
func main() {ctx := context.TODO()cancelCtx, cancel := context.WithCancel(ctx)defer cancel()go func() {for {<-cancelCtx.Done()// 被上游取消,结束业务处理return/**业务处理*/}}()/**业务处理*/
}
设计要点
-
创建cancelCtx时,核心是找到最近的cancelCtx类型的祖先,将自己加到该祖先的children里面,这样祖先被cancel时,自己也会被cancel,达到级联取消的效果
-
如果找不到,就新起一个goroutine监听父的done信号和自己的done信号
-
go func() {select {case <-parent.Done():child.cancel(false, parent.Err())case <-child.Done():} }() - 为什么要监听父的done信号?因为无法加到父的children字段里,只能通过监听父的done信号来达到级联取消的效果
- 为什么要监听自己的?如果自己比父早被取消,该gouroutine也可以退出
-
-
如果父没有done信号,说明父永远不会被取消,什么也不用监听
- 这样只有在cancel方法被调用时才会取消
Done方法用一个双重检测的方式,确保c.done只被初始化一次
如果第一次不检测在功能上完全没有问题,但原子操作比加锁快,性能更好
func (c *cancelCtx) Done() <-chan struct{} {d := c.done.Load()// 第一次检测if d != nil {return d.(chan struct{})}c.mu.Lock()defer c.mu.Unlock()d = c.done.Load()// 第二次检测if d == nil {d = make(chan struct{})c.done.Store(d)}return d.(chan struct{})
}
cancel方法主要干了两件事:
- 关闭自己的done:
close(done) - 遍历children,挨个调用child的cancel方法
timerCtx
通过funcWithDeadline(parent Context, d time.Time) (Context, CancelFunc)
可以创建一个带超时控制的ctx
WithTimeout底层调的
WithDeadline,两者本质上一样
timerCtx用装饰器模式,在cancelCtx上增加了超时的功能
用 time.AfterFunc开启计时器,时间到了执行cancel方法
c.timer = time.AfterFunc(dur, func() {c.cancel(true, DeadlineExceeded)
})
设计要点
-
如果parent也是timerCtx,且parent的过期时间比当前ctx的过期时间早,就只创建一个cancelCtx,避免开启定时器的开销
- 为什么?因为parent时间到被cancel时,自己时间没到,因此自己的定时器一定不会被触发,还不如不创建
sync.Mutex和sync.RWMutex
用于保护需要被保护的资源
-
哪些资源需要被保护?
- 可能被多个goroutine同时读写
-
哪些资源不需要被保护?
- 只在单个goroutine中操作
- 多个goroutine只读该资源
封装模式
如果一个资源需要被保护,则需要暴露出被封装的方法,而不是将资源和锁都暴露出去,让用户自己考虑要不要加锁,怎么加锁
错误使用:
var Resource map[string]interface{}
var ResourceLock sync.Mutex
正确使用:
// 包私有
var resource map[string]interface{}
var resourceLock sync.Mutex// 封装Get
func GetResource(key string) interface{} {resourceLock.Lock()defer resourceLock.Unlock()return resource[key]
}// 封装Set
func SetResource(key string, value interface{}) {resourceLock.Lock()defer resourceLock.Unlock()resource[key] = value
}
这样保证对resource的使用不会出错,也体现封装的设计模式
双重检测
对于check and do模式,一般采用双重检测的模式进行操作,即:
- 加读锁
- 执行check,如果不满足要求直接返回
- 释放读锁
- 如果满足要求,加写锁
- 再check一次,如果还满足要求,执行do
例如,要对一个map实现LoadAndStore功能:如果某个key存在,就返回对应的value,否则插入kv
type SafeMap struct {data map[string]interface{}lock sync.RWMutex
}func (m *SafeMap) LoadAndStore(key string, value interface{}) (interface{}, bool) {m.lock.RLock()// 第一次checkoldVal, ok := m.data[key]m.lock.Unlock()if ok {return oldVal, true}m.lock.Lock()defer m.lock.Unlock()// 第二次checkoldVal, ok = m.data[key]if ok {return value, true}m.data[key] = valuereturn value, false
}
-
第一次check能不能不要?
- 第一次check其实可以不要,不会影响流程的正确性,但在读多写少的场景下先加读锁check一次的性能更高
-
为什么需要加写锁后再check一次?
- 因此释放读锁后,可能其他goroutine已经插进来执行了do操作,如果这里不再检测一次,就会在check不成功的情况执行do操作,不满足check and do的语义
读优先和写优先
读写锁中有读优先和写优先两种模式:
- 读优先:已经有写锁在等待的情况下,还能成功加读锁
- 写优先:已经有写锁在等待的情况下,不能再加读锁,这样当之前的读锁都释放后,写锁就能加成功
一般的语言,例如go都是是写优先,防止写饥饿
Mutex原理
加锁流程:

mutex的结构如下:
type Mutex struct {state int32sema uint32
}
- state是锁的核心状态,加锁就是将state修改为某个值
- sema用于阻塞,唤醒goroutine
流程图中的要点:
-
自旋:分为快路径:一次性的自旋和慢路劲:多次自旋
-
快路径:CAS将其从0改为加锁状态
-
慢路径:什么情况下可以进行慢路径自旋?
- 自旋次数小于4
- cpu核数大于1
- 至少存在1个其他运行的P
- P的本地队列为空
-
-
为什么有饥饿模式和正常模式?
-
正常模式:效率更高,新来的goroutine可以和队列中的goroutine抢锁,因为新来的已经占着cpu,大概率能拿到锁。为什么效率更高?避免了先阻塞进入队列,在被唤醒执行的调度开销
-
饥饿模式:保证公平,防止饥饿,新来的不能抢锁,需要进入队列等待
-
什么情况下锁变为饥饿模式?
- 某个goroutine等待超过1ms
-
什么情况退出饥饿模式?
- 队列只剩下一个goroutine
- 等待时间小于1ms
-
注意事项
- 加锁和解锁需要成对出现,推线使用defer解锁
- 锁都是不可重入的,若需要重入功能需要自己封装
- 对于读多写少的场景使用
RWLock
sync.Pool
当需要缓存对象时,可以使用sync.Pool
从pool中获取时,会先看池中有没有,如果没有创建新的对象
gc时pool会释放一部分资源
pool的优点:
- 减少内存分配开销
- 内存分配少了,gc 的压力也会变小
对象重置
当对象要被复用时,需要重置掉对象的属性,避免两个请求共用相同的用户数据
例如gin框架在从pool中取出gin.Context时,先重置其属性,再交给用户的方法使用:
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {c := engine.pool.Get().(*Context)c.writermem.reset(w)c.Request = req// 重置属性c.reset()engine.handleHTTPRequest(c)engine.pool.Put(c)
}
-
放回去之前重置还是取出来重置?
- 放回去之前重置:如果对象占用空间很大,放回去之前重置能减少pool的内存占用
- 取出来重置:如果对象占用空间不大,则放回去之前重置的对象可能被gc回收,导致白做工,此时用取出来重置的方式比较好
pool原理
-
如果我们自己设计会怎么实现?
- 首先考虑用一个channel来存放对象,但这样放入,获取都要加锁
- 全局锁性能不高,那可以用分段锁的方式,每个P一个队列,用锁保护
sync.Pool的实现原理:
-
每个p有一个poolLocalInternal对象
-
poolLocalInternal包含
private和shared -
private只会被对应的p使用
- 也就是说往private放入数据,从private获取数据都不需要加锁
-
shared指向poolChain
- poolChain从整体上来说是一个双向链表
- poolChain的每个节点poolDequeue都是一个循环数组


-
为什么poolDequeue设计成循环数组?
- 即数组的优点:一次性分配好内存,对cpu 缓存友好
Get

Put

设计要点
-
为什么从队头放入数据,从队尾获取数据?
- 在分段锁的基础上,进一步减少锁竞争的几率,这样只有在同时操作一个双向链表的同一个节点时才会加锁
-
从victim中获取数据可以从private获取,而偷取其他poolChain的数据可能需要加锁,为什么可能需要加锁的优先级更高?
- 因为sync.Pool希望victim中的数据被尽快回收,只有在偷不到的情况下才尝试从victim中获取
注意事项
-
sync.Pool的容量设置和淘汰策略,用户无法手动控制,其中淘汰策略完全依赖gc
- gc每次触发,都会把victim中的数据清空,将正常数据放入victim
- 若需要手动控制容量,可以用装饰器模式包装pool,自己决定大对象不放入pool,超过一定数量不放入
-
为什么需要victim,而不是每次gc都把正常数据清空?
- 防止性能抖动,这样正常数据要经过两次gc才会被清空gingin
使用gin的框架的一个坑
如果在业务处理中需要开goroutine,不能直接将gin.Context传给新的goroutine
如果直接传过去,当本次请求结束后该ctx被复用时,此时就有两个goroutine同时在使用该ctx:
- 原先请求中新开的goroutine:g1
- 新的业务请求goroutine:g2
而g1需要使用的用户数据是原先请求的,但当新业务请求到来时,g2会给ctx设置新的用户数据
导致用户数据发生窜用
因此当需要在业务请求中开goroutine时,需要调用Copy方法复制一份gin.Context
sync.WaitGroup
用于同步多个goroutine之间的工作:
- Add(1):开启子任务,state+1
- Done():结束子任务,state-1
- Wait():阻塞等待,直到所有子任务执行完毕
设计原理
WaitGrout其实需要保存3个信息:
- 多少个子任务
- 多少个goroutine在等待
- 等待的goroutine阻塞在哪个队列上
type WaitGroup struct {state1 uint64state2 uint32
}
- state1:高32位记录子任务个数,低32位记录多少个goroutine在等待
- state2:信号量,用于挂起和唤醒等待的goroutine
Add流程:
- 给state1高32位加delta(delta可以是负数)
- 如果加完后高32位大于0(还有其他子任务),或者低32位等于0(没有waiter),返回
- 如果高32位等于0,且低32位不等于0,挨个唤醒waiter
Wait流程:
- 如果高32位为0,说明没有子任务,直接返回
- 阻塞到队列上,直到被Add唤醒
注意事项
需要注意state的+1和-1需要成对出现:
- 加多了:Wait的goroutine会永久阻塞
- 减多了:直接panic
因此可以用errgroup来完成WaitGroup的功能,因为其封装了对+1-1的操作,保证一定成对出现
channel
导致goroutine泄露
channel使用不当时,会导致goroutine泄露:
- 只发送不接收:该goroutine会一直等到有其他goroutine接收,但一直没被接收
- 只接收不发送
- 读写nil的channel
实现原理
channel主要的结构有两个:
-
存放缓存数据的队列
- channel用循环数组实现
-
存放发送接收的等待队列
发送流程:

-
为什么有接收者,可以直接将数据给接收者?
- 数据不用经过缓冲区绕一次,性能更高
- 有接收者时,说明缓存区一定没有数据,不会破坏队列先入先出的特性
接收流程
